Overfitting 방지로 Weight Decay와 Dropout이 많이 사용됩니다. 한 번 알아봅시다
Weight Decay란?
신경망 학습시 weight가 너무 큰 값을 가지지 않도록 패널티를 주는 방식입니다. loss func에 L2 Norm을 더하는 방식으로 구현되어 있습니다.
L2 Norm의 수학적 정의
L2 노름은 개별 weight의 제곱의 합이라고 생각하시면 됩니다.
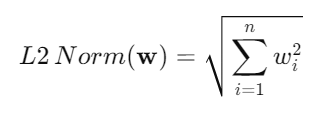
Weight Decay의 적용 방법
각 weight의 제곱의 합을 loss func에 더함으로써 너무큰 weight가 존재할 시 loss func 값이 커져서 패널티를 부여받게 됩니다.
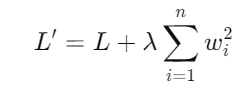
여기서 𝐿은 원래의 손실 함수, λ는 Weight Decay의 강도를 조절하는 매개변수로, 이 값을 조절함으로써 가중치에 대한 규제의 강도를 변경할 수 있습니다. λ가 크면 클수록 모델의 가중치는 더 작은 값을 가지려고 하며, 이는 모델이 더 간단해지도록 유도합니다.
Weight Decay 효과
Weight Decay를 사용함으로써 모델은 훈련 데이터의 노이즈나 불필요한 패턴을 덜 학습하게 됩니다. 이는 모델이 훈련 데이터에만 지나치게 최적화되는 것을 방지하고, 미지의 데이터에 대해서도 좋은 성능을 발휘할 수 있도록 돕습니다. 결과적으로, Weight Decay는 모델의 과적합을 줄이고, 테스트 데이터에 대한 성능을 개선합니다.
Dropout 이란?
신경망의 노드일부를 무작위로 삭제하면서 학습하는 방법입니다. 신경망이 더욱 더 복잡해지면서 Weight Decay만으로는 오버피팅을 방지하기 어려워지고 있습니다. 이런 이유로 Dropout방법이 나오게 되었습니다.
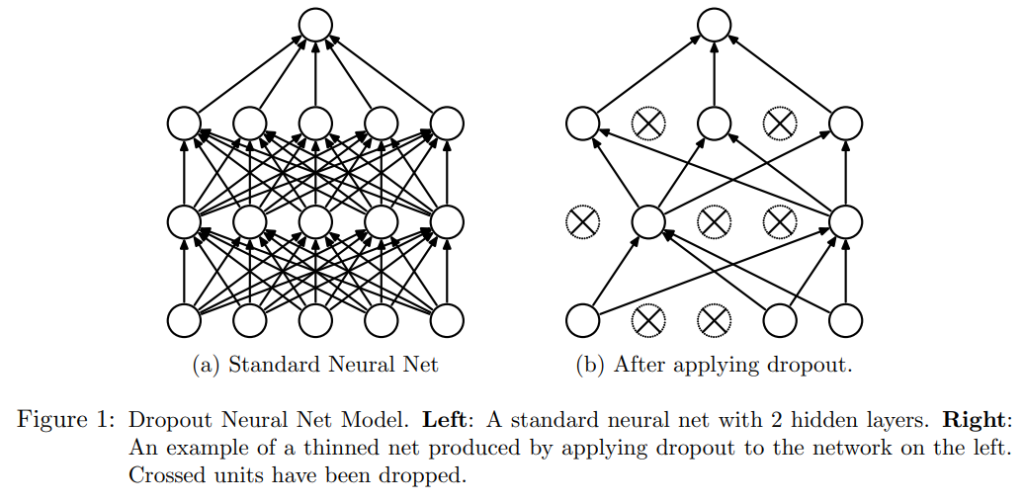
Train과 Test에서 다르게 동작하는 Dropout 기법
Dropout은 Train과 Test에서 다르게 작동합니다. train 때는 무작위로 매번 배치 때마다 다르게 삭제하고, test때는 노드를 삭제하지 않고 모든 노드를 사용하되, 각노드에 삭제한 비율을 곱해서 순전파를 진행합니다.
앙상블과 Dropout 기법의 닮은점
머신러닝에서 앙상블많이 사용하시죠? 앙상블은 개별모델을 합쳐서 한가지 출력을 내는 방식입니다. 드랍아웃도 학습마다 다른 노드들이 활성화 되므로 모델 앙상블기법과 닮았다고 할 수 있습니다.