{kind=link}
기본적인 Rnn Generate 모델입니다. 주석으로 설명해놨으니 참고해보세요!
RNN 언어생성모델
Python
# utf-8 인코딩 사용
# 필요한 모듈 임포트
import sys
sys.path.append('..') # 부모 디렉토리를 시스템 경로에 추가하여 다른 모듈을 임포트할 수 있도록 설정
import numpy as np # 수치 계산을 위한 numpy 모듈 임포트
from common.functions import softmax # 소프트맥스 함수 임포트
from ch06.rnnlm import Rnnlm # Rnnlm 클래스 임포트
from ch06.better_rnnlm import BetterRnnlm # BetterRnnlm 클래스 임포트
# Rnnlm 클래스를 상속하여 새로운 RnnlmGen 클래스 정의
class RnnlmGen(Rnnlm):
# 단어 ID 시퀀스를 생성하는 함수
def generate(self, start_id: int, skip_ids: list[int] = None, sample_size: int = 100) -> list[int]:
"""
언어 모델로부터 단어 ID 시퀀스를 생성합니다.
매개변수:
- start_id: 최초 시작 단어의 ID.
- skip_ids: 생성 중에 건너뛸 단어 ID들의 리스트. 이 리스트에 속하는 단어는 샘플링되지 않는다. <unk>(희소단어), N(숫자) 등
- sample_size: 생성할 단어의 수.
반환값:
- 생성된 단어 ID들의 리스트.
"""
word_ids = [start_id] # 생성된 단어 ID들을 저장할 리스트, 시작 단어 ID로 초기화
x = start_id # 현재 단어의 ID
while len(word_ids) < sample_size: # 생성된 단어의 수가 샘플 크기보다 작은 동안 반복
x = np.array(x).reshape(1, 1) # 현재 단어 ID를 numpy 배열로 변환하고 모양을 (1, 1)로 변경
score = self.predict(x) # 모델을 사용하여 다음 단어의 점수를 예측
p = softmax(score.flatten()) # 예측된 점수에 소프트맥스 함수를 적용하여 확률로 변환
# 확률에 따라 다음 단어를 샘플링
sampled = np.random.choice(len(p), size=1, p=p)
# skip_ids에 포함되지 않은 단어일 경우에만 단어 ID에 추가
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled # 샘플링된 단어 ID를 현재 단어 ID로 설정
word_ids.append(int(x)) # 단어 ID 리스트에 추가
return word_ids # 생성된 단어 ID 리스트 반환
# LSTM 상태(h, c)를 반환하는 함수
def get_state(self) -> tuple[np.ndarray, np.ndarray]:
"""
LSTM 레이어의 현재 상태를 반환합니다.
반환값:
- h: LSTM의 은닉 상태
- c: LSTM의 셀 상태
"""
return self.lstm_layer.h, self.lstm_layer.c
# LSTM 상태(h, c)를 설정하는 함수
def set_state(self, state: tuple[np.ndarray, np.ndarray]) -> None:
"""
LSTM 레이어의 상태를 설정합니다.
매개변수:
- state: 설정할 (h, c) 상태의 튜플
"""
self.lstm_layer.set_state(*state)
더나은 RNN기반 언어생성모델
위 코드에서 발전시킨 모델입니다.
Python
# utf-8 인코딩 사용
# 필요한 모듈 임포트
import sys
sys.path.append('..') # 부모 디렉토리를 시스템 경로에 추가하여 다른 모듈을 임포트할 수 있도록 설정
import numpy as np # 수치 계산을 위한 numpy 모듈 임포트
from common.functions import softmax # 소프트맥스 함수 임포트
from ch06.better_rnnlm import BetterRnnlm # BetterRnnlm 클래스 임포트
# BetterRnnlm 클래스를 상속하여 새로운 BetterRnnlmGen 클래스 정의
class BetterRnnlmGen(BetterRnnlm):
# 단어 ID 시퀀스를 생성하는 함수
def generate(self, start_id: int, skip_ids: list[int] = None, sample_size: int = 100) -> list[int]:
"""
언어 모델로부터 단어 ID 시퀀스를 생성합니다.
매개변수:
- start_id: 시작 단어의 ID.
- skip_ids: 생성 중에 건너뛸 단어 ID들의 리스트.
- sample_size: 생성할 단어의 수.
반환값:
- 생성된 단어 ID들의 리스트.
"""
word_ids = [start_id] # 생성된 단어 ID들을 저장할 리스트, 시작 단어 ID로 초기화
x = start_id # 현재 단어의 ID
while len(word_ids) < sample_size: # 생성된 단어의 수가 샘플 크기보다 작은 동안 반복
x = np.array(x).reshape(1, 1) # 현재 단어 ID를 numpy 배열로 변환하고 모양을 (1, 1)로 변경
score = self.predict(x).flatten() # 모델을 사용하여 다음 단어의 점수를 예측하고 1차원 배열로 변환
p = softmax(score).flatten() # 예측된 점수에 소프트맥스 함수를 적용하여 확률로 변환
# 확률에 따라 다음 단어를 샘플링
sampled = np.random.choice(len(p), size=1, p=p)
# skip_ids에 포함되지 않은 단어일 경우에만 단어 ID에 추가
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled # 샘플링된 단어 ID를 현재 단어 ID로 설정
word_ids.append(int(x)) # 단어 ID 리스트에 추가
return word_ids # 생성된 단어 ID 리스트 반환
# 모든 LSTM 레이어의 상태(h, c)를 반환하는 함수
def get_state(self) -> list[tuple[np.ndarray, np.ndarray]]:
"""
모든 LSTM 레이어의 현재 상태를 반환합니다.
반환값:
- 각 레이어의 (h, c) 상태 튜플의 리스트
"""
states = [] # 각 레이어의 상태를 저장할 리스트
for layer in self.lstm_layers: # 각 LSTM 레이어에 대해
states.append((layer.h, layer.c)) # 레이어의 은닉 상태와 셀 상태를 튜플로 추가
return states # 상태 리스트 반환
# 모든 LSTM 레이어의 상태(h, c)를 설정하는 함수
def set_state(self, states: list[tuple[np.ndarray, np.ndarray]]) -> None:
"""
모든 LSTM 레이어의 상태를 설정합니다.
매개변수:
- states: 각 레이어의 (h, c) 상태 튜플의 리스트
"""
for layer, state in zip(self.lstm_layers, states): # 각 레이어와 해당 상태를 짝지어
layer.set_state(*state) # 레이어의 상태를 설정
Seq2Seq
seq2seq는 RNN을 연결한 신경망입니다. Encoder 클래스와 Decoder 클래스로 구현합시다.
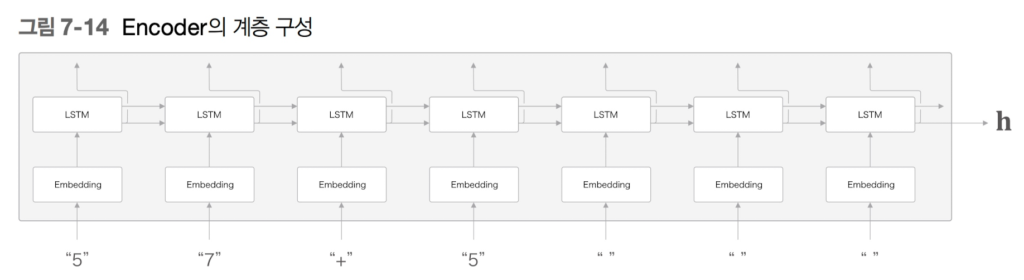
Python
# utf-8 인코딩 사용
# 필요한 모듈 임포트
import sys
sys.path.append('..') # 부모 디렉토리를 시스템 경로에 추가하여 다른 모듈을 임포트할 수 있도록 설정
from common.time_layers import * # TimeEmbedding, TimeLSTM, TimeAffine 등 시간 축 기반 레이어 임포트
from common.base_model import BaseModel # BaseModel 클래스 임포트
import numpy as np # 수치 계산을 위한 numpy 모듈 임포트
# 인코더 클래스 정의
class Encoder:
def __init__(self, vocab_size: int, wordvec_size: int, hidden_size: int):
"""
인코더 초기화.
매개변수:
- vocab_size: 어휘의 크기 (고유한 단어 수)
- wordvec_size: 단어 벡터의 크기
- hidden_size: LSTM 은닉 상태의 크기
"""
V, D, H = vocab_size, wordvec_size, hidden_size # 변수 설정
rn = np.random.randn # 난수 생성 함수
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f') # 임베딩 가중치
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') # LSTM 입력 가중치
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') # LSTM 은닉 가중치
lstm_b = np.zeros(4 * H).astype('f') # LSTM 바이어스
# TimeEmbedding 및 TimeLSTM 레이어 초기화
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
# 파라미터와 기울기 초기화
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None # 은닉 상태 초기화
def forward(self, xs: np.ndarray) -> np.ndarray:
"""
인코더의 순전파 계산.
매개변수:
- xs: 입력 시퀀스 (단어 ID 배열)
반환값:
- 최종 은닉 상태
"""
xs = self.embed.forward(xs) # 임베딩 계층의 순전파
hs = self.lstm.forward(xs) # LSTM 계층의 순전파
self.hs = hs # 은닉 상태 저장
return hs[:, -1, :] # 시퀀스의 마지막 은닉 상태 반환
def backward(self, dh: np.ndarray) -> np.ndarray:
"""
인코더의 역전파 계산.
매개변수:
- dh: 출력의 기울기
반환값:
- 입력에 대한 기울기
"""
dhs = np.zeros_like(self.hs) # 은닉 상태와 동일한 형상의 배열 생성
dhs[:, -1, :] = dh # 마지막 은닉 상태에 대한 기울기 설정
dout = self.lstm.backward(dhs) # LSTM 계층의 역전파
dout = self.embed.backward(dout) # 임베딩 계층의 역전파
return dout # 입력에 대한 기울기 반환
# 디코더 클래스 정의
class Decoder:
def __init__(self, vocab_size: int, wordvec_size: int, hidden_size: int):
"""
디코더 초기화.
매개변수:
- vocab_size: 어휘의 크기 (고유한 단어 수)
- wordvec_size: 단어 벡터의 크기
- hidden_size: LSTM 은닉 상태의 크기
"""
V, D, H = vocab_size, wordvec_size, hidden_size # 변수 설정
rn = np.random.randn # 난수 생성 함수
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f') # 임베딩 가중치
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') # LSTM 입력 가중치
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') # LSTM 은닉 가중치
lstm_b = np.zeros(4 * H).astype('f') # LSTM 바이어스
affine_W = (rn(H, V) / np.sqrt(H)).astype('f') # Affine 계층의 가중치
affine_b = np.zeros(V).astype('f') # Affine 계층의 바이어스
# TimeEmbedding, TimeLSTM, TimeAffine 레이어 초기화
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
# 파라미터와 기울기 초기화
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine): # 각 레이어에 대해
self.params += layer.params # 파라미터 추가
self.grads += layer.grads # 기울기 추가
def forward(self, xs: np.ndarray, h: np.ndarray) -> np.ndarray:
"""
디코더의 순전파 계산.
매개변수:
- xs: 입력 시퀀스 (단어 ID 배열)
- h: 인코더에서 전달된 은닉 상태
반환값:
- 출력 점수 (단어 분포)
"""
self.lstm.set_state(h) # LSTM의 초기 상태 설정
out = self.embed.forward(xs) # 임베딩 계층의 순전파
out = self.lstm.forward(out) # LSTM 계층의 순전파
score = self.affine.forward(out) # Affine 계층의 순전파
return score # 출력 점수 반환
def backward(self, dscore: np.ndarray) -> np.ndarray:
"""
디코더의 역전파 계산.
매개변수:
- dscore: 출력 점수에 대한 기울기
반환값:
- 인코더의 은닉 상태에 대한 기울기
"""
dout = self.affine.backward(dscore) # Affine 계층의 역전파
dout = self.lstm.backward(dout) # LSTM 계층의 역전파
dout = self.embed.backward(dout) # 임베딩 계층의 역전파
dh = self.lstm.dh # LSTM의 은닉 상태에 대한 기울기
return dh # 인코더의 은닉 상태에 대한 기울기 반환
def generate(self, h: np.ndarray, start_id: int, sample_size: int) -> list[int]:
"""
디코더를 사용하여 단어 시퀀스를 생성.
매개변수:
- h: 인코더에서 전달된 초기 은닉 상태
- start_id: 생성 시작 단어의 ID
- sample_size: 생성할 단어 수
반환값:
- 생성된 단어 ID들의 리스트
"""
sampled = [] # 생성된 단어 ID를 저장할 리스트
sample_id = start_id # 현재 생성할 단어 ID
self.lstm.set_state(h) # LSTM의 초기 상태 설정
for _ in range(sample_size): # 샘플 크기만큼 반복
x = np.array(sample_id).reshape((1, 1)) # 현재 단어 ID를 배열로 변환
out = self.embed.forward(x) # 임베딩 계층의 순전파
out = self.lstm.forward(out) # LSTM 계층의 순전파
score = self.affine.forward(out) # Affine 계층의 순전파
sample_id = np.argmax(score.flatten()) # 가장 높은 점수를 가진 단어 ID 선택
sampled.append(int(sample_id)) # 선택된 단어 ID를 리스트에 추가
return sampled # 생성된 단어 ID 리스트 반환
Seq2seq 클래스
Encoder 클래스와 Decoder 클래스를 연결하면 최종적으로 아래와 같은 구현이 됩니다.
Python
# utf-8 인코딩 사용
# 필요한 모듈 임포트
import sys
sys.path.append('..') # 부모 디렉토리를 시스템 경로에 추가하여 다른 모듈을 임포트할 수 있도록 설정
import numpy as np # 수치 계산을 위한 numpy 모듈 임포트
from common.time_layers import * # TimeEmbedding, TimeLSTM, TimeAffine 등 시간 축 기반 레이어 임포트
from common.base_model import BaseModel # BaseModel 클래스 임포트
# Seq2seq 클래스 정의
class Seq2seq(BaseModel):
def __init__(self, vocab_size: int, wordvec_size: int, hidden_size: int):
"""
Seq2seq 모델 초기화.
매개변수:
- vocab_size: 어휘의 크기 (고유한 단어 수)
- wordvec_size: 단어 벡터의 크기
- hidden_size: LSTM 은닉 상태의 크기
"""
V, D, H = vocab_size, wordvec_size, hidden_size # 변수 설정
# 인코더, 디코더, 손실 계층 초기화
self.encoder = Encoder(V, D, H) # 인코더 초기화
self.decoder = Decoder(V, D, H) # 디코더 초기화
self.softmax = TimeSoftmaxWithLoss() # 손실 계층 초기화
# 파라미터와 기울기 초기화
self.params = self.encoder.params + self.decoder.params # 인코더와 디코더의 파라미터 합산
self.grads = self.encoder.grads + self.decoder.grads # 인코더와 디코더의 기울기 합산
def forward(self, xs: np.ndarray, ts: np.ndarray) -> float:
"""
Seq2seq 모델의 순전파 계산.
매개변수:
- xs: 입력 시퀀스 (단어 ID 배열)
- ts: 목표 시퀀스 (단어 ID 배열)
반환값:
- 손실 값
"""
# 디코더 입력 시퀀스와 목표 시퀀스를 분리
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs) # 인코더를 통해 입력 시퀀스를 인코딩하여 은닉 상태 획득
score = self.decoder.forward(decoder_xs, h) # 디코더를 통해 점수 계산
loss = self.softmax.forward(score, decoder_ts) # 손실 계산
return loss # 손실 반환
def backward(self, dout: float = 1) -> None:
"""
Seq2seq 모델의 역전파 계산.
매개변수:
- dout: 손실에 대한 기울기 (기본값: 1)
반환값:
- 인코더 입력에 대한 기울기
"""
dout = self.softmax.backward(dout) # 손실 계층의 역전파
dh = self.decoder.backward(dout) # 디코더의 역전파
dout = self.encoder.backward(dh) # 인코더의 역전파
return dout # 인코더 입력에 대한 기울기 반환
def generate(self, xs: np.ndarray, start_id: int, sample_size: int) -> list[int]:
"""
Seq2seq 모델을 사용하여 시퀀스 생성.
매개변수:
- xs: 입력 시퀀스 (단어 ID 배열)
- start_id: 생성 시작 단어의 ID
- sample_size: 생성할 단어 수
반환값:
- 생성된 단어 ID들의 리스트
"""
h = self.encoder.forward(xs) # 인코더를 통해 입력 시퀀스를 인코딩하여 은닉 상태 획득
sampled = self.decoder.generate(h, start_id, sample_size) # 디코더를 사용하여 단어 시퀀스 생성
return sampled # 생성된 단어 ID 리스트 반환