
{kind=link}
구현한 CBOW 모델은 말뭉치가 커지면, 계산량이 매우 많아집니다. 그래서 2가지 개선을 합니다.
첫번째, Embedding이라는 계층을 도입한다.
두번째, 네거티브 샘플링 이라는 새로운 손실함수를 사용한다.
이 두가지 개선으로 진짜 실제로 사용하는 word2vec이 완성됩니다.
Embedding계층으로 word2vec 개선
어휘가 100만단어고, 은닉층이 100개인 CBOW모델을 생각해보자
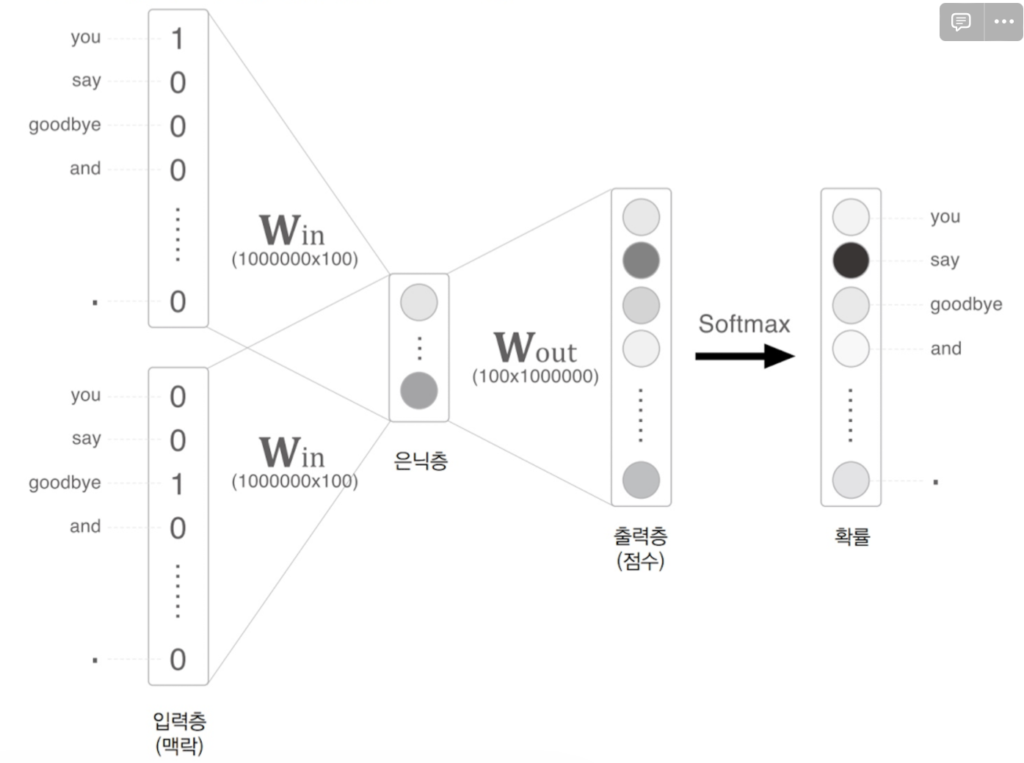
위와 같은 신경망은 학습 시 너무 많은 시간과 자원이 소요된다.
원핫의 메모리가 너무 커진다. 100만 어휘만 되어도 이렇게 커진다.
이런 문제를 Embedding 계층으로 개선한다.
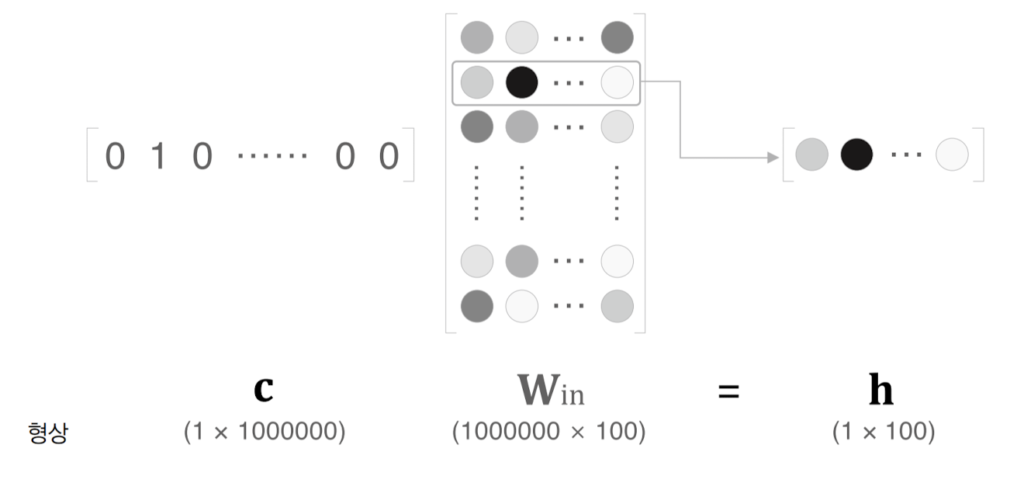
말뭉치가 100만 어휘일때 100만행의 MatMul연산을 해야하지만 사실상 그냥 Win의 특정행을 추출하는 것일 뿐이다. 100만 행을 전부 곱하는 연산을 할 필요가 없다.
이렇게 Win으로부터 단어ID에 해당하는 벡터를 추출하는 계층을 Enbedding계층이라고 한다.
Embedding layer 구현
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out역전파는 어떻게 구현하면 될까? Embedding계층은 그저 가중치(W)를 다음층에 전달할 뿐이다. Backword()도 특정행의 기울기를 전달해주면 된다.
def backward(self, dout):
dW, = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout) // np.add.at(A, idx, B)는 B를 A의 idx번째 행에 더함.
return None기울기(dW)의 요소들을 전부 0으로 한뒤 전달받은 기울기(dout)를 dW의 특정행(idx)에 더해주면 된다.
할당하지 않고 더하는 이유는 idx가 [0, 2, 0, 4] 라고했을 때 할당한다면 0이라는 index가 두개 이므로 나중에 갱신되는 값이 덮어써 버린다. 그래서 더해야한다.
다음글에서는 Softmax계층과 출력층의 연산을 Negative Sampling으로 개선하는 방법을 알아보자!